ベーマガ世代、ChatGPTとゼロからRPGを作る旅
第22章:トーナメントでわくわく、コロシアム戦!
トーナメントにはロマンがある。
残念ながら、小説でトーナメントを面白く描くのはなかなかに難物。
チャレンジしたいと思ったことはあるが、書き上げたことはない。
しかし、漫画だと、ドラゴンボールの天下一武道会、ワンピースのドレスローザのコロシアムなど……名作・名場面にいとまがない。
そして……いうまでもなく、RPGゲームとトーナメントの相性は抜群!
いやあ、人生初RPGで、ここまで凝ったゲームにするつもりはなかったんだけど、相棒(ChatGPT)がいれば、このぐらいお茶の子さいさいでしょ!
トーナメントでわくわく
さて、いよいよ王都の一つ目の目玉イベント、コロシアムでのトーナメントの実装である。
王道の3戦、と決めたのだが……
せっかくなのでヒロインにより敵の種類を変えよう……と、また悪い癖が出てきて、敵の数が増殖してきた。
実際に戦える敵はある程度絞りつつ、トーナメントなので、キャラとしては8人を準備。
控室で他の選手と会話し、情報収集させたい。
となると、誰と誰がバトルするのか分かったほうが盛り上がる。
よし、トーナメント表を「使う」と、表が見られるようにしよう!
すでに実装済みの文字列のオーバーレイ処理。
これを画像に書き換えればいいのでは……?
などと考え、ChatGPTに相談したところ、以下のようにオーバーレイ処理に画像の引数を追加する案をしてくれた。
function showOverlay(content, direction = "right", duration = 1000, callback = null, imageSrc = null) {
overlayEffect = {
content,
image: imageSrc ? new Image() : null,
showDirection: direction,
hideDirection: null,
startTime: performance.now(),
duration,
phase: "in",
callback,
opacity: 1,
};
if (imageSrc) overlayEffect.image.src = imageSrc;
}
うーん。
画像に文字を重ねるならこの方式がよさそうだが、今やりたいことは画像を表示するだけ。
もともとある引数(content)が文字列なら文字表示、画像なら画像表示とするほうが簡単そうだ。
contentってニュートラルな名前だけど、ここに渡したものが画像かどうかdrawOverlayEffect()側で判定するってのはどうだろう?
あり!
むしろ そっちのほうが設計としてスマート だと思うよ。
ということで、設定部分のshowOverlayはいじらず、その先の実際の表示(drawOverlayEffect())に出し分け処理を追加した。
// 🟦 文字列ならテキスト描画
if (typeof c === "string") {
ctx.fillStyle = "white";
ctx.fillRect(0,0,CANVAS_WIDTH,CANVAS_HEIGHT);
ctx.fillStyle = "black";
ctx.font = "40px PixelMplus, sans-serif";
ctx.textAlign = "center";
ctx.textBaseline = "middle";
ctx.fillText(c, CANVAS_WIDTH/2, CANVAS_HEIGHT/2);
}
// 🟨 Imageなら一枚絵描画
else if (c instanceof HTMLImageElement && c.complete) {
ctx.fillStyle = "white";
ctx.fillRect(0,0,CANVAS_WIDTH,CANVAS_HEIGHT);
const img = c;
const scale = Math.min(CANVAS_WIDTH / img.width, CANVAS_HEIGHT / img.height);
const w = img.width * scale;
const h = img.height * scale;
ctx.drawImage(img, (CANVAS_WIDTH - w)/2, (CANVAS_HEIGHT - h)/2, w, h);
}
オーバーレイはdirectionで設定した値により、左右上下からスライドイン・スライドアウトする仕様だったが、移動せずにふわっと現れたり消えたりする機能も追加した。
また、アイテムの「使う」から利用すると、アイテムウィンドウ側とキー操作がバッティングするので、もろもろ自力でデバッグした。
絵の上からメニューウィンドウがかぶってしまうので、表示順も入れ替えた。
「使う」だと使い勝手が悪かったので、「見る」からオーバーレイで画像表示、ESCやスペースキーを押すと元に戻れるようにし、よし完成!
……と思ったが、ここまできて、たいへんな事に気がついた。
冷静に考えると主人公の名前が可変なので、画像のトーナメント表が厳しかったw
主人公名の可変問題、めっちゃあるあるで笑ったw
(紙に印刷済みの固定画像だと、そこがどうしても詰むんだよね……)
代案①:文字ベースで説明する(王道・一番自然)
代案②:UI ベースの “テキスト版トーナメント表” を overlay で見せる
代案③:キャラの顔アイコンで見せる(ちょっと豪華)
・・・笑われてしまったorz
いやー、あるあるなら先に教えてよ!
気を取り直して、テキスト版トーナメント表を検討してみることにした。
ヒロインごとに3パターンの対戦表を渡してみたのだが、なぜだか相棒(ChatGPT)、主人公の対戦相手の3人だけのUIを作ろうとする。
等幅フォントを使ってテキストだけで表を作れないか相談すると、できるよ、とこんなのを書いてきた。
▲トーナメント表……にはどうやっても見えない。
おおう、なんかChatGPTのUI画面上で見ると既に崩れてるんだけど、
以下のフォントで頑張って作ってみるよ ┌ ┐ └ ┘ ─ │ ├ ┤ ┬ ┴ ┼
うん、ChatGPT の画面は等幅じゃないから絶対にズレるんだけど、
実際のゲーム画面(Canvas)では
きっちり等幅フォント(PixelMplus / Mplus1Code など)で描画されるので問題なし!
つまり、
ここでズレて見えるのは「ChatGPT UIのフォントのせい」で、
ゲーム内では綺麗に揃うので安心して大丈夫。
いやいや、幅がどうとかそういうレベルの問題じゃないのだが。
LLMはこういう上下左右とかの幾何学的なテキスト配置には弱いんで、ここで論破するのは時間の無駄と判断。
ここはこっちで頑張るしかない。
こういう感じになると思うんだけど。 縦書きなのでちょっとプログラム面倒だけど、①②③④⑤⑥が主人公の名前(名前が短い場合は全角スペース)に置き換わる。
┌───┴───┐
┌─┴─┐ ┌─┴─┐
┌┴┐ ┌┴┐ ┌┴┐ ┌┴┐
① セ メ ガ ロ ガ サ レ
② レ イ ル ド ル リ |
③ ナ ジ ダ ン ュ ヴ
④ イ ン ァ
⑤ ン
⑥
これを見たChatGPTは、全キャラクターの名前を縦書きにして差し替える仕組みを作ろうとしてくれた。
function verticalName(name, length = 6) {
const chars = [...name];
while (chars.length < length) chars.push(" "); // 全角スペース
return chars.slice(0, length);
}
さらに勝敗も入れたいと言うと、表を作ろうとしてくれたのだが……
sylphi: {
round1: { player: "勝", opponent: "負", opponentName: "セレナ" },
round2: { player: "勝", opponent: "負", opponentName: "ガルダイン" },
……
},
全キャラを入れてテストとなると、素直にめんどくさい。
それに、プレイヤーと敵キャラだけの対戦順だけでなく、全キャラの勝敗を入れていきないとトーナメント表にならない。
パルル以外の勝敗も表現していくから、8人のリストが必要じゃない?
まあ、最終形が9個しかないので全パターンテキストで用意しておいて差し替えるだけでもいいかも。
どこまで“動的生成”するか vs “固定テキストを差し替えるか” の選択で、結論から言うと今の段階では「固定テキスト9個を用意」方式が最強にコスパが良いと思う。
ChatGPT(GPT-5)もこのところ素直なので、最初のアイディアに固執することはない。
私が当初考えていた通り、こんな感じに名前だけ置き換えることになった。
function makeVerticalName(name) {
const chars = [...name];
while (chars.length < 6) chars.push(" "); // 全角スペース
return chars;
}
function injectPlayerName(template, name) {
const v = makeVerticalName(name);
return template.map(line =>
line.replace("①", v[0])
.replace("②", v[1])
.replace("③", v[2])
.replace("④", v[3])
.replace("⑤", v[4])
.replace("⑥", v[5])
);
}
そうそう、このぐらいシンプルでいいんだよ。
これだけシンプルならバグが潜り込む隙もない。
テストケースも、主人公の名前がMAX(6文字)の場合、それ未満の場合の2種類で済む。
この後、背景色を足して、文字を中央寄せして(こういうのは私がやるとバグりそうだが、相棒(ChatGPT)がやると一発でクリア)、無事トーナメント表ができあがった!
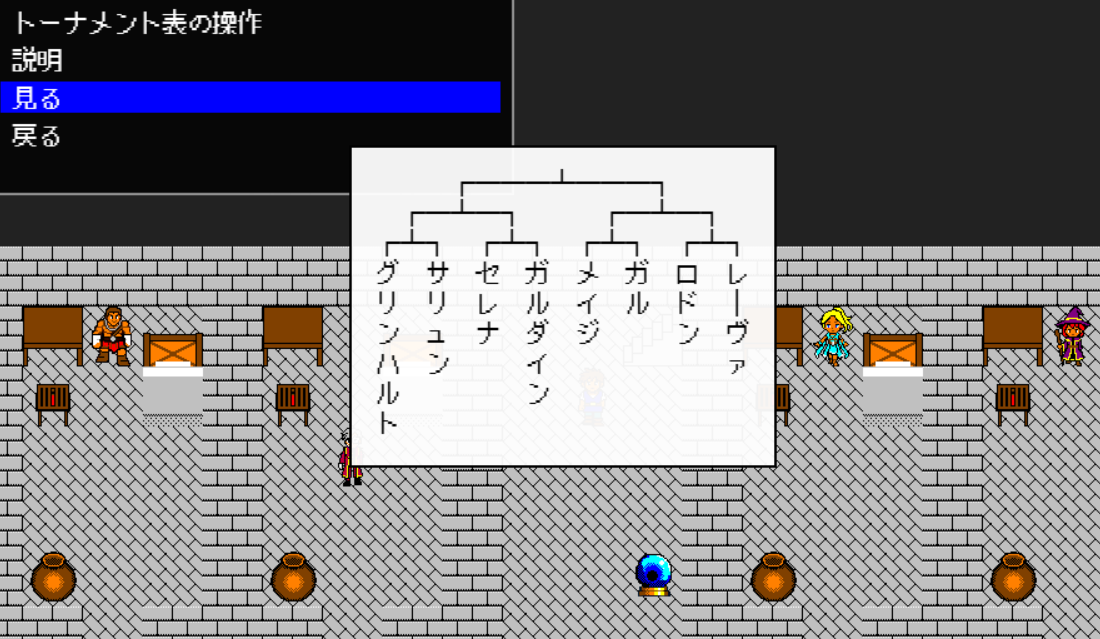
▲トーナメント表完成!
いや~、テンションあがりますな~。
分身の術!
せっかくなので敵キャラにより攻撃パターン(攻略パターン)も工夫したいところ。
α版以降、状態異常も追加しているが、さらに、分身の術なども実装していくことにした。
バトル時の行動として、分身の術を発動するようにしたら、本体をコピーして攻撃しない分身を作るようにしたのだが……
当然ながらそう一筋縄ではいかなかった。
まずは分身の術発動中に、もう一度術が発動して無限増殖するバグが。
これは想定範囲内なので、分身発動中は、二度目の分身を行わないように修正。
次に気になったのは、分身の残スタミナが少なく(1ポイント固定にしていた)、どれか分身がモロバレな点。
こちらは比率を計算することで、本体と同じスタミナに見えるように調整した。
ちょっと厄介だったのが、「分身は攻撃してこない」ようにしていたのに、なぜか攻撃してきてしまうところ。
以下の行動選択部分、「||」だとattackChanceが0でも1と判定されてしまうようなので、未定義の時だけ上書きされるよう「??」に書き換えた。
誤)
let illusionChance = behavior.illusionChance;
if(enemy.illusionActive && enemy.illusionActive > 0) illusionChance = 0;
const choice = weightedRandom([
{ key: 'flee', weight: behavior.fleeChance || 0 },
{ key: 'wait', weight: behavior.waitChance || 0 },
{ key: 'attack', weight: behavior.attackChance || 1 },
...
{ key: 'illusion', weight: illusionChance || 0 }
]);
正)
let illusionChance = behavior.illusionChance;
if(enemy.illusionActive && enemy.illusionActive > 0) illusionChance = 0;
const choice = weightedRandom([
{ key: 'flee', weight: behavior.fleeChance ?? 0 },
{ key: 'wait', weight: behavior.waitChance ?? 0 },
{ key: 'attack', weight: behavior.attackChance ?? 1 },
...
{ key: 'illusion', weight: illusionChance ?? 0 }
]);
また、本体コピー時に「浅いコピー」を使ってしまっていたため、第10章でも登場したstringfyで「深いコピー」を実装した。
分身を使う敵は、戦う側からすると厄介だが、プログラムを実装してみて、意図通り分身がすぅっと消えた時は実にいい気分。「やった!」とガッツポーズである。
敵キャラのデザイン
コロシアムで対戦する敵キャラのデザイン。
小ボス/中ボスに該当するので、これも重要である。
ChatGPT×DALLE-Eに描いてもらったのだが、どういうわけか、どうにも足が短く描かれがち。
ゲームやアニメなどで足が長い人間を見慣れすぎているせいかもしれないが……
足は画像加工で延ばしたのだが、苦労したのは踊り子。
魅惑のダンスで主人公を翻弄する設定なので、もう少し色気がほしいというか……
鳥山明風の武道使いならこれでもいいのかもしれないけど、手足の包帯みたいなテーピングが邪魔である。
キュロットみたいなのも消したい。
絵柄は変えたくなかったので、オープニング絵本の時もお世話になった画像専門AI、stable-diffusionを使うことにした。
stable-diffusionにはさまざまなモデルがあるが、以前ChatGPTに相談してFF系ビットマップが作れるというモデルを導入済みである。
https://civitai.com/models/7371/revanimated
ダウンロード方法:
①上記リンクにアクセス
②ページの右側にある「Download」ボタンをクリック
③.safetensors 形式を選択(推奨:revAnimated_v122.safetensors など最新版)
④ダウンロードファイルを
→ stable-diffusion-webui\models\Stable-diffusion
フォルダにコピー
webui-user.batを起動すると、ローカルWEBサーバが立ち上がりブラウザが開かれる。
paint2paintのInpaintで、変更したい箇所だけ白塗りでマスクし、プロンプト(英語)で指示。
A high-resolution pixel art of a fantasy dancer woman in a blue flowing dress.
Remove bandages from her arms and legs, replace the short shorts with a skirt,
add crossed sandal straps on her legs, fix the ribbon in her hair (clean edges, no noise),
add flowing blue fabric from her wrist bracelets similar to the smaller sprite version.
8-bit SNES RPG style, detailed pixel texture, consistent lighting.
これで生成すると、マスクした部分が書き直される。
……はずなのだが……

▲ ちょっと下半身が小さめで頭でっかちに見える元画像

▲ gimpで足を延ばし、直したいところをInpaintでマスクしてみる。

▲ 再生成したけど腿の白いのが消えない……

▲ 修正を繰り返す。テーピングは消えたが、どうしても腿に輪っかを残したいらしい。
なかなか思う通りに行かず、gimpで手作業で色を置いて、マスクして修正してもらうのを繰り返し……

▲ いったんこの画像で進行中です……

▲ 一度マスク忘れたらぜんぜん違う画風に
疲れてきたので、左上の画像で進めることにした。
AIを使っても、思った絵に近づけるには地道な努力が必要だ。
次回は戦闘を盛り上げる「構え」の導入と、品質を安定させるための単体テストについて書くよ!